
What Is Text Analytics? We Analyze the Jargon
Market researchers, software vendors and bloggers like to hype up the radical newness of advanced analytics technologies. Sometimes, you’d think we were on the eve of putting Skynet into production.
But text analytics is pretty much as old as the technology of language itself. Traditionally, people just called it “reading.”

_Text: A legacy technology
(untitled by Procsilas Moscas is licensed under CC BY 2.0)_
The difference is that now, software can read text as easily as human beings, not to mention much more quickly.
With text analytics, you can spot patterns in massive collections of textual data that an individual human mind could never detect.
Sounds great, right? It is. The catch with text analytics, like many technologies in the advanced analytics space, is that it’s also complex and difficult.
To bring light to the befuddled, we’ll share some insights from Gartner’s Market Guide for text analytics and break down some of the jargon you need to know to use these tools.
Here’s what we’ll cover:
OK, So What Is Text Analytics?
Needlessly Complex Jargon Explained!
OK, So What Is Text Analytics?
There’s much more to text analytics than just algorithms and complex software, because its object is language instead of conveniently normalized data in a data warehouse.
This means that before the machine can perform pattern recognition, it needs to extract the linguistic meaning from textual data. In other words, the machine must read the text before it can truly be analyzed.
This is why many text analytics tools structure the text mining workflow as a pipeline, running from raw data to output:
Basic Text Processing Pipeline
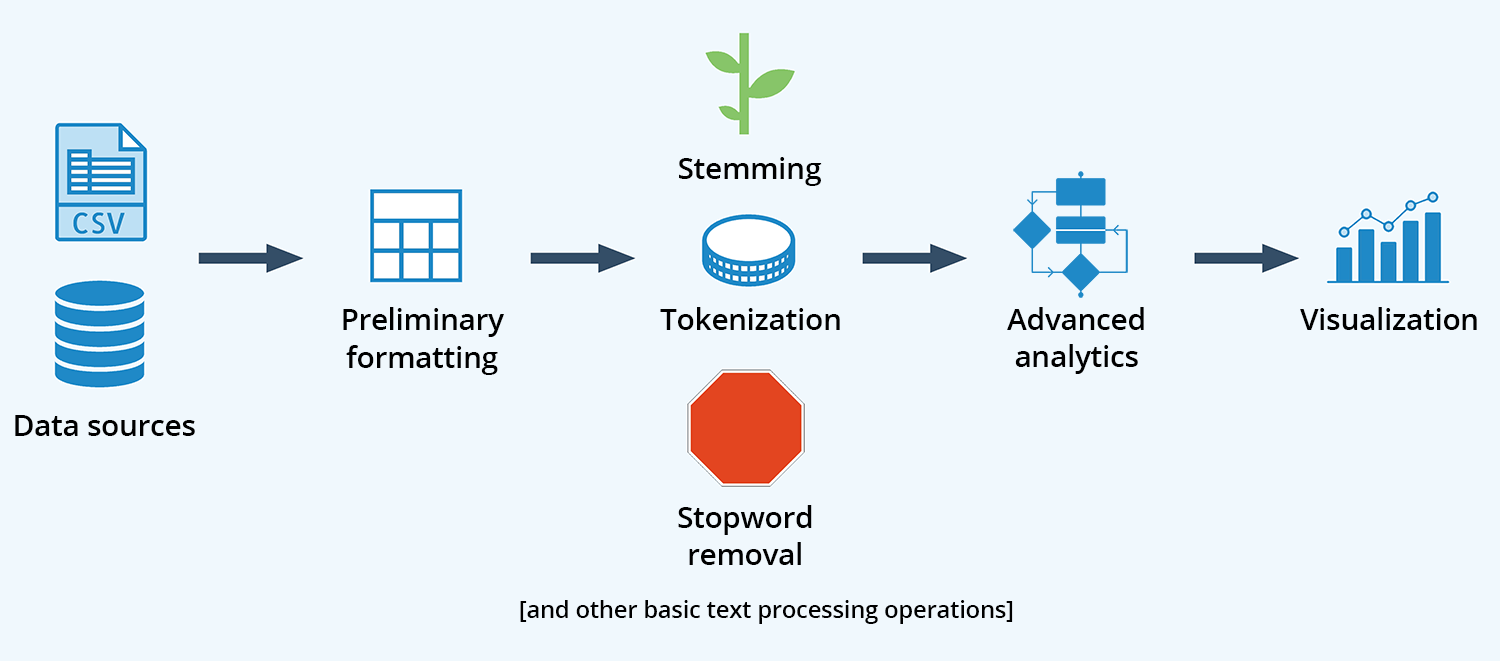
According to Gartner’s Market Guide for Text Analytics (this content is available to Gartner clients) by Alan D. Duncan, Alexander Linden, Hanns Koehler-Kreuner, Ehtisham Zaidi and Shubhangi Vashisth, “At a high level, a text analytics system is a pipeline process comprising three stages:
Text acquisition and preparation
Processing and analysis
Output (that is, visualization, presentation and deployment).”
Text acquisition and preparation is the most straightforward stage. Many text analytics tools can read directly from flat files such as Excel files, relational databases and web sources, e.g., Twitter and Facebook. The text is then prepared using some basic operations shown in the above diagram.
The magic happens at the processing and analysis stage. Gartner’s report explains that text analytics involves “a combination of both linguistic and machine-learning statistical techniques in processing and analysis of text source. Where the linguistic technique is provided for data preparation and customization of the model, the machine-learning technique will be applied to get a more rapid result for weighting. That means the text source will be ‘parsed’ and ‘chunked’ linguistically before any run through of the machine-learning algorithms for classification.”
We won’t get into the nitty-gritty details of how linguistic techniques differ from machine-learning based techniques here, other than to note that this is a key way in which vendors differentiate their offerings. To truly understand linguistic approaches to text analytics, you literally need a Ph.D. in linguistics.
Instead, let’s look at some of the more basic steps you can easily perform yourself with a free or open-source text mining solution. These steps are the linguistic “parsing” and “chunking” steps Gartner mentions.
In other words, they aren’t the final steps in text analytics, but necessary operations that must be performed before machine-learning algorithms can be applied.
Needlessly Complex Jargon Explained!
You can see in the above chart that you typically need to perform a number of basic text processing operations before applying advanced analytics to your data. Let’s now cover some of these, in addition to a few of the more common advanced analytics techniques used in text mining:
Stopword removal. Textual data contains lots of little insignificant yet highly common words: “to,” “for,” “of,” “the” etc. If you’re analyzing the frequency of words in a document, these will always surface to the top.
Stopword removal is the process of filtering out these words to look for longer, more significant words. Many text analytics solutions come with built-in stopword dictionaries for different languages, and you can also build your own.
Thomas Ott, marketing data scientist at RapidMiner (the developer of a popular open-source data science platform that supports text mining), explains why businesses need to use custom dictionaries:
“I was working with a financial services company to look at support ticket information, and they have a lot of machine IDs from different computers, servers and so on. That cluttered up a lot of different things in their support tickets, so they built their own stopword dictionary.”
Tokenization. In Ott’s words, “Tokenization looks at the spaces between the words as word boundaries in order to ‘cut’ words from the text string at those points.”
This isn’t always obvious as it would seem—for instance, is “garbage truck” one word or two? Tokenization is a first step toward structuring text for further analysis, as otherwise text is treated as an unstructured “string.”
Once the string has been broken into individual words or “tokenized,” you can determine word frequency in the document and begin identifying relationships between words.
Businesses will thus need to ensure that common compound words in their operations are properly tokenized for further analysis. Most text-mining tools allow users to customize tokenization rules.
Bag-of-words. This operation breaks down a document into its constituent words, regardless of grammar and order. It’s never an end-step in a text mining operation, but rather a first step toward further analysis. Bag-of-words analysis is thus a type of tokenization.
The difference is that tokenization operations typically preserve the order of “tokens” in the string, while the bag-of-words model disregards word order to focus on word frequency.
**
Stemming (a.k.a. “lemmatization”).** Words don’t just have a single form, but many forms based on their grammatical purpose. For instance, “was,” “are,” “is” etc. are all forms of the verb “to be.” Stemming reduces words in a document to their basic forms, including words that are significant to the company’s operations and goals.
Once you perform these basic operations, further analytics can be applied to textual data in order to recognize patterns. We’ll just cover one important technique here:
Cluster analysis. In the context of text mining, cluster analysis involves classifying words into groups, such that words in a given group are more related to each other than they are to words in other groups.
This is done through the application of algorithms such as k-means and x-means. Ott explains how these algorithms work: “In k-means, you say that the variable ‘K’ is the number of clusters you want.”
“Maybe you want to segment your data into two groups, five groups etc.—you have to put that in there, and then the algorithm builds around that. In x-means, you don’t know what the optimal amount of clusters is, so you specify a minimum of, say, two, and a maximum of, say, 60. The algorithm will then run an analysis and output the optimal number of clusters.”
Clustering is a powerful way to spot relationships and trends in massive collections of textual data. It can also be a first step toward sentiment analysis (e.g., using text mining to identify consumer emotions), since words relating to brands, products, services and other entities can be grouped via clustering.
Where Should I Go From Here?
Gartner cautions that “while most text analytics offerings support a single use case well, vendors’ claims of more general capabilities should be treated with caution.”
Linguistic meaning depends on context, which means that many text analytics deployments are highly specific to a business model or problem. Some vendors will work well for use cases such as fraud detection, but they might not work at all for sentiment analytics use cases.
Despite the obvious promise of text analytics, the market remains highly fragmented and confusing. Gartner observes that “the current growth of the market is inhibited by a significant shortage of text analytics talent within both IT departments and business units.
A number of factors keep text analytics from becoming a more pervasive, easy-to-use business solution: still-immature technology; difficulty meshing with a larger ecosystem; and the enormous diversity of use cases.”
Thus before you begin submitting RFIs, you need to get a feel for how text processing operations work in a real text-mining pipeline. The best way to do this is to use the dozens of free and open-source text-mining tools on the market.
We’ve written a guide to introduce you to the easiest-to-use tools. Within minutes of installing, you can start building a text-mining pipeline. Within hours, you’ll have an excellent understanding of the immense promise as well as the significant challenges of this emerging technology.